Getting the right diff lines to show up in present-me was actually very confusing, and very interesting.
I'm still not exactly sure I have it working correctly 100% of the time, but it's much better than it used to be, and I have somewhat of an understanding of how it works.
The following overview uses this as an example and gh api to illustrate.
The actual implementation in present-me uses the go-github client.
The API
First things first, we need to have a record of what we're getting from the API.
Present-me uses PR Reviews, which have attached comments to generate the page itself.
Once we have a REVIEW_ID, we have the required parameters to get all of the comments:
gh api repos/stanistan/present-me/pulls/56/reviews/1419621494/comments | jq '
.[0]
| del(.user, .diff_hunk, .body, ._links, .reactions)
'
output
{
"id": 1189251393,
"node_id": "PRRC_kwDOFP2I5M5G4olB",
"url": "https://api.github.com/repos/stanistan/present-me/pulls/comments/1189251393",
"pull_request_review_id": 1419621494,
"path": "frontend/pages/[org]/[repo]/pull/[pull]/review-[review].vue",
"position": 43,
"original_position": 43,
"commit_id": "e91d383fab97c1ca02d01806ff05d7a4a0dc6a8a",
"created_at": "2023-05-10T00:49:04Z",
"updated_at": "2023-05-10T01:03:55Z",
"html_url": "https://github.com/stanistan/present-me/pull/56#discussion_r1189251393",
"pull_request_url": "https://api.github.com/repos/stanistan/present-me/pulls/56",
"author_association": "OWNER",
"original_commit_id": "e91d383fab97c1ca02d01806ff05d7a4a0dc6a8a"
}
The .body is the text of the comment, and can be markdown. For present-me, if you have a
number prefix, you can order the output of the display.
body
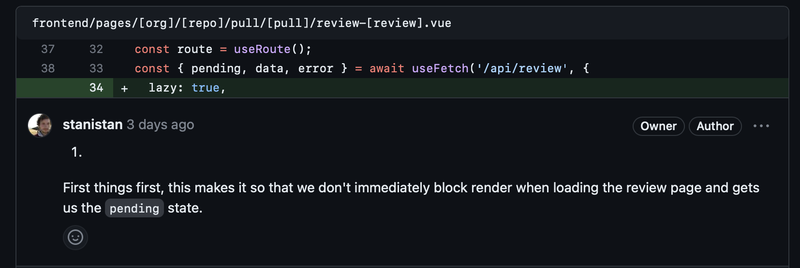
1.
First things first, this makes it so that we don't immediately block render when loading the review page and gets us the `pending` state.
Diff Hunk
The .diff_hunk field is part of the raw diff that you'd get from
running git show on the commit. In this case, it's pretty close to what we show,
but it's a little off, we'd ideally only show the last 3 lines.
@@ -34,8 +28,10 @@
useHead({
title: 'present-me',
});
+
const route = useRoute();
const { pending, data, error } = await useFetch('/api/review', {
+ lazy: true,
The heading of the hunk (@@ -34,8 +28,10 @@) describes the
start line and number of lines of the prior version of the file,
and the start line and number of lines of the new version of the file.
In this case:
- the old version of the file started on line
34and ended at42, - and the new version starts at
28and ends at38.
It's easy to forget that the file will change in multiple places!
If we look at our API response, the only information that looks like it may
be somewhat relevant is "position": 43, but that's fully out of the range
that we're in. What the heck.
Back to the API
It turns out that there isn't actually enough information in the review comment
to choose the desired output lines. If you use a different API once you have
the comments themselves, you can get line numbers on the comment.
# output snipped to the relevant fields
gh api repos/stanistan/present-me/pulls/comments/1189251393
# {
# "start_line": null,
# "original_start_line": null,
# "line": 34,
# "original_line": 34,
# "side": "RIGHT"
# }
These are useful!
What's in a Diff Hunk?
We described the metadata of the diff hunk before, but what's actually going on here?
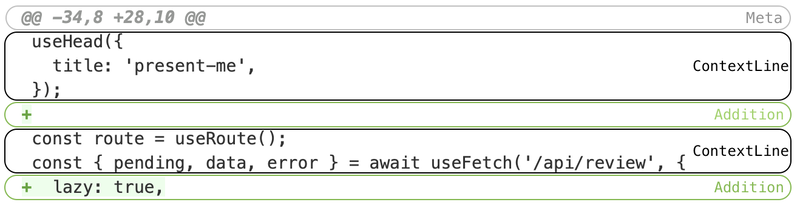
- We have
Context, which is not an addition or removal in the diff - An
Additionof one empty line - More
Contextof lines that aren't changing - And an
Additionat the end
I think of these as individual chunks in the diff if you go line by line.
Picking Lines
The beginning (or the end):
- We use the
side=RIGHTfrom the API to know that the lines the API response refers to are the right side of the diff, the after file. - This corresponds to a line range of
28-38per the thunk metadata. - We only count lines in the version of the file that we're looking at! So we skip any lines that would be deletions. There are none in this sample.
- Given we're going to line
34-- that is the last line:lazy: true.
We now have the end line of the diff that we're looking at (and want to show), and we know that the top three lines are not included (when looking at github vs the diff hunk).
There are two cases here:
- Where the comment specifies a
start_line - Where the start line is implicit
We're going to cover (2) because it is more interesting.
It looks like GitHub tries to show you 3 or 4 lines of context on the comment around the line it was placed, depending on what it deems to be useful. This is definitely a heuristic method.
We can hardcode this patch to 3 lines, but then other ones would be wrong (where it is clearly 4).
Chunking!
First thing we do is group the raw lines coming in from the diff into chunks based
on what the diff perfix is. It's either an empty space ( ), plus (+), or minus
(-).
For the example above we have 4 chunks.
Counting
We only count lines when they are relevant for the version of the file we're looking at. So if we're looking at the right side, we count additions, and don't count deletions since the metadata tells us the range of lines the hunk is for.
for idx, line := range lines {
// N.B. we skip the first one since it's where the metadata is
if idx == 0 {
continue
}
// sometimes in testing lines are fully trimmed out -- we assume
// in this case that it's an "empty context line"
if len(line) == 0 {
line = " "
}
prefix := line[0:1]
if lineNo >= p.start && lineNo <= p.end {
if prefix != lastPrefix {
pushChunk()
}
chunk = append(chunk, line)
}
// track if we're changing prefixes
lastPrefix = prefix
// track if we're moving forward to the desired place
if !strings.HasPrefix(line, p.hunkRange.IgnorePrefix) {
lineNo++
}
}
pushChunk()
Picking Chunks
Yes this is a two pass process! Once we have our chunks, we go through them to see if they would be useful, filtering out extra lines by their chunk (what a phrase).
We do this entire operation as a stack! We know that the line (last line we've accumulated) is where the comment was placed, so we go through the chunks we found in reverse order to see if we want to add more information to display.
- A useful chunk is non empty and is part of the counting scheme.
- And if we have gotten do a diff that is larger than 3 lines (auto-selected) we can stop accumulating changes once we've gotten to the first non-useful chunk.
- Otherwise we keep accumulating them.
var (
out []string
numChunks = len(chunks)
chunkIdx = numChunks - 1
)
for chunkIdx >= 0 {
chunk := chunks[chunkIdx]
if auto && len(out) >= 3 && !chunk.isUseful(p.hunkRange.IgnorePrefix) {
break
}
out = append(chunk.lines, out...)
chunkIdx--
}